如何设计Git服务器(小丑的看法)
在传统的 git 后端服务中,首要面对的挑战就是存储容量上限问题和用户并发访问高负载问题。本文简要概述 git 后端服务的架构,以及一些有用的文章。
1. 单机+冷备模式
gitlab 社区版提供了单机版,可以通过配置 git hooks 触发同步任务,将数据保存备份到备机。
存在的问题是同步任务经常出现卡住,同步失败,对象缺失等问题,备机无法保证实时最新,也无法保证数据完整性,备机不能开启读服务。
2. 单机+分布式存储
该场景希望使用分布式存储解决存储容量上限问题的问题,这样存储可以无限扩展,具体如下所示:

通过上图可以看见只使用了一个应用集群操作分布式文件系统,试想一下若新建多个应用集群,然后使用类似 dns 轮询分发请求的方式是否可以降低用户高并发访问时的负载?
答案是否定的,Gitee 曾在该架构下发生过事故,主要原因是分布式存储系统并不适合用在 Git 这种海量小文件的场景下,因为 Git 每一次的操作都需要遍历大量的引用和对象,导致每一次操作整体耗时非常多。
3. 数据分片 + 主备模式
3.1 只分片
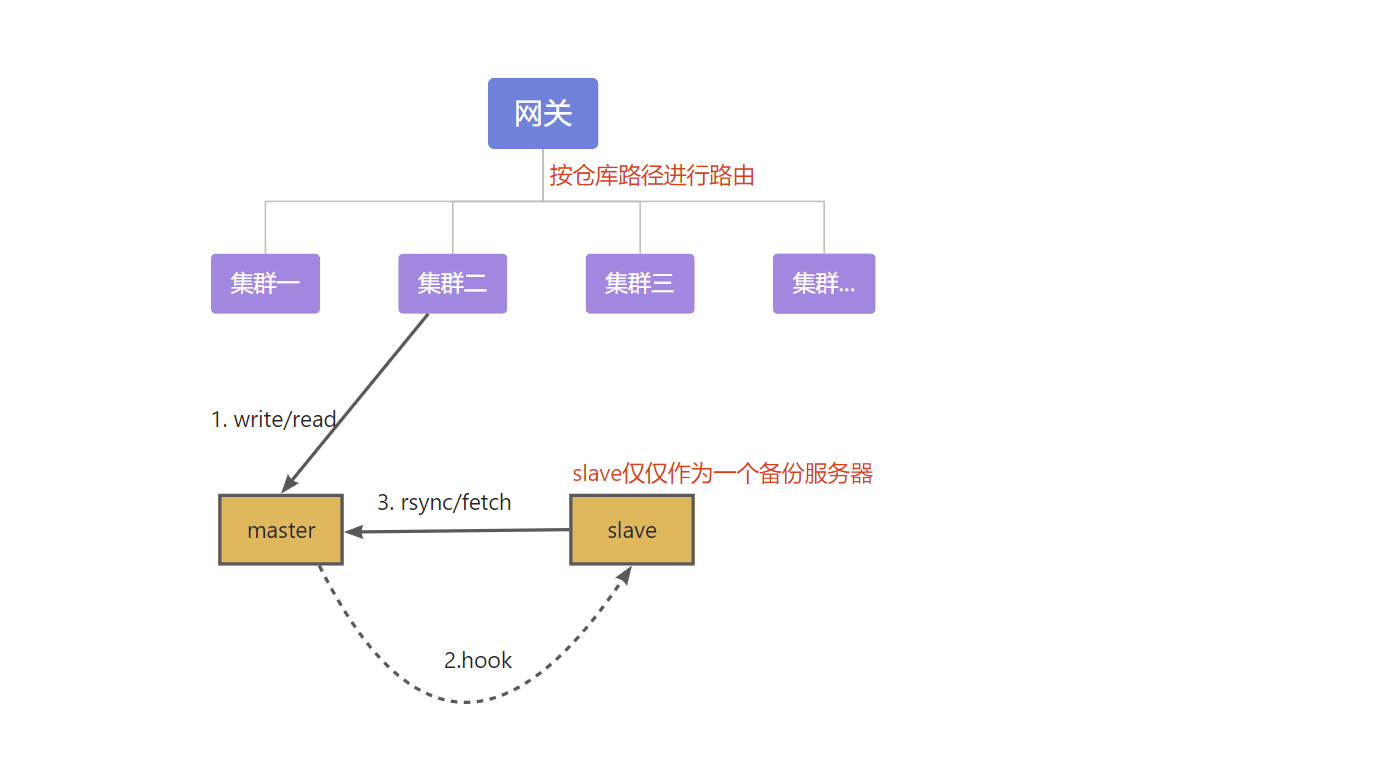
上图为数据分片模式下的架构模型,其中集群内的 slave 由于仅仅是在主机写入完成后才会发起 hook 消息到从机(slave),然后 slave 复制 master 数据到 slave。显然 slave 的同步可能会失败或缺失、不完整,所以该模式下所有的读写请求都是 master 来处理。
在这种模式下一个集群只有一台主机提供服务,由于网络带宽和机器资源的限制,当集群的访问超出 master 最大 qps 时, 服务器就会出现不稳定的状况。当前 coding-git 就是运行在这种模式之下的,所以运行效率差强人意。
3.2 分片+读写分离
该点其实就是在 2.2.1 的基础上考虑,如何判定 master 和 slave 的仓库对等?也就是读到备机的数据是最新的,且完整的?最简单的一个步骤如下所示:
- 由 master 节点,进行写操作,结束后计算并更新当前的 depot 的 hash 值;
- 通过 git hook 向 slave 发起同步任务;
- slave 同步完 master 最新数据之后,计算并更新当前 depot 的 hash 值;
- 当新的读请求过来时,先查看是否有跟 master 的 depot hash 值相同的 slave,如果有,再根据负载均衡算法选择一台 slave,提供读服务。
3.3 存在的问题
当某个分片的 master 节点发生异常(服务 crash 或服务器宕机等),会导致整个分片无法正常提供服务,下面是几点可能会产生的问题,摘自阿里巴巴代码平台架构的演进之路:
- 可用性: 由于读写操作是分离的,所以在写服务器故障期间,服务的写功能是无法使用的; 对于单片而言,写操作是单点的,一台服务波动则整个分片都波动。
- 性能:主备机器在同步上需要额外的时间开销。对于松散文件、文件压缩的 Git 仓库,这个耗时比单文件拷贝耗时更久。
- 安全: 用户侧的短时间内的瞬时操作,对于节点同步来说可能是并发的,无法保证同步中的事务顺序。
- 成本:同分片写,主备机器要求规格完全一致,但由于接收的请求不同,存在严重的资源消耗不均;当同步的小文件多时,对延时敏感。
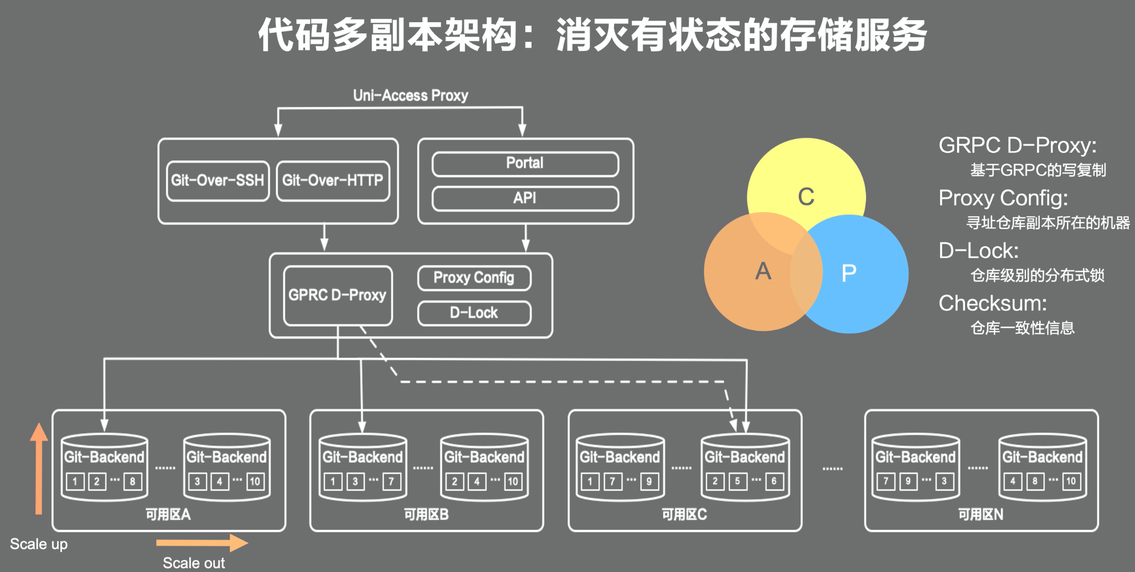
4. 多读多写
该节是阿里代码平台的一个实现方案,具体特征有:多写(写时复制)、无状态服务、快速校验仓库一致性。